
I Passed My AWS AI Practitioner Cert, But Let’s Talk About What Actually Happened#
Welcome back friend. I passed the AWS Certified AI Practitioner (AIF-C01) exam on March 31st, 2026 and my score was 761 out of 1,000. The passing threshold is 700, so yes, I passed, but if you’re expecting a victory lap, this isn’t that kind of post. My Cloud Practitioner score was 776, which means I scored higher on the easier exam with a simpler study process. The AI Practitioner took me roughly seven weeks, and somewhere in the middle of it I built an entire custom learning application. I have thoughts about all of that, and I want to be honest about what happened rather than just saying “I studied hard and passed.”
The Same Wall, Again#
If you read my CCP post, you know the pattern. I took Stephane Maarek’s Udemy course, went through it section by section, took notes, and felt reasonably confident by the end. Then I took the first practice exam and scored 63%. For the CCP I pushed through that, reviewed my misses, and climbed into the 80s within a few days.
For the AI Practitioner I did the same thing. I completed Maarek’s Udemy course, also completed the AWS Skill Builder learning plan (so two full courses this time), and sat down for the first practice exam feeling prepared. 64%. Two courses, weeks of lectures and notes, and I’m staring at a 64%.
That number was frustrating in a way that’s hard to describe if you haven’t been there. It’s not that the material was too hard. I understood the concepts when I read about them, I could follow the explanations, I could nod along to the lectures. But when I sat in front of a practice question asking me to pick between Amazon Comprehend and Amazon Textract for a specific business scenario, I couldn’t reliably pull the right answer out of my head. The concepts were familiar but not retrievable, and there’s a real difference between those two things. A 64% score is what that difference looks like.
The Idea#
Around this time I started looking into why my study approach wasn’t working and came across a research paper by Dunlosky et al. (2013) that evaluated ten common learning techniques and rated each one by how well it actually produces durable retention. The two highest-rated techniques were practice testing (actively retrieving information from memory rather than re-reading it) and distributed practice, which means spreading study sessions over time rather than cramming. The two lowest-rated were re-reading and highlighting, which of course was basically my entire study method.
So I decided to build something, because that’s what I do. I’m a platform engineer, and when I see a problem I want to build a system that solves it. The result was TeachMyHuman (TMH), a local Python web application built with Flask that delivers a retrieval-practice study experience. The idea was straightforward: read a section of learning material, then immediately get quizzed on it, with questions interleaved across all previously studied sections so you’re constantly forced to recall concepts from earlier in the course rather than just the section you finished reading. Everything runs locally on your machine with no SaaS, no hosted backend, and no ongoing cost. The question bank and learning material are pre-generated from official AWS source documents and distributed as a static release artifact. The concept was sound. The execution is where things went sideways.
Building the Tool Instead of Using It#
Here’s the part where I have to be honest with myself. I started building TMH as a study aid, and within a week TMH became the main quest while studying became the side quest.
I built a six-theme system with light and dark modes and implemented a settings page with a font size picker. I spent an entire session debugging Mermaid diagram rendering in dark mode, which involved bypassing Mermaid’s entire theme system and post-processing the SVG DOM directly with MutationObservers and double requestAnimationFrame calls. The kind of problem that’s genuinely interesting to solve and has absolutely nothing to do with passing an AWS exam. I designed a favicon using Gemini for image generation and ImageMagick for transparency processing. I migrated my entire development workflow from the browser-based Claude interface to Claude Code CLI running inside a VS Code dev container, which required debugging nerdctl container networking, volume persistence for authentication tokens, and Dockerfile build failures caused by expired GPG keys in the base image.
And that’s just the application work. I also started building a local ML pipeline for automatically generating TMH learning content and question banks from source PDFs, using Docling for PDF ingestion, Ollama for embeddings and local inference, and Qdrant as a vector database. The irony of that one isn’t lost on me: I was supposed to be studying for an exam that covers data pipelines, RAG architectures, and embedding models, and instead of studying those concepts I was implementing them. I designed a 3-node Raspberry Pi 5 cluster for running k3s with a custom image via cloud-init and a baking script. I spent an evening experimenting with aider and local AI models on my RTX 5060 Ti. I researched whether I should buy an RTX 5090 or wait for the Mac Studio M5 Ultra. I designed a content format migration from JSON to Markdown with YAML front matter, wrote three deferred feature specification documents for features I wasn’t going to build yet, explored forming a Texas LLC to commercialize TMH, and prepared for a job interview with Vultr for a Storage Performance Engineer role.
Every single one of those things is individually reasonable, and some of them are genuinely valuable, but none of them are studying for the exam. The total time from starting to study to actually sitting for the exam was about seven weeks when a focused effort should have taken me three, maybe four weeks. I probably spent less than half my total effort on actual study activities like reading material, doing retrieval practice, and taking practice tests. The rest went to engineering work that felt productive but didn’t directly improve my exam readiness.
The uncomfortable truth is that engineering is my comfort zone and sitting down to quiz myself on content I don’t fully know yet is not. When both options were available, I consistently chose the comfortable one. That’s not laziness (the total hours I put in were substantial) but it was misallocated effort. Building infrastructure around a learning tool is more comfortable than actually doing the difficult, uncomfortable work of testing yourself on material you haven’t mastered.
The Hurdles#
Beyond the focus problem, there were real hurdles with the study process itself. The first Maarek practice exam at 64% was discouraging, but I expected improvement once I started using TMH, and TMH did work. My scores within the application were consistently 80% or higher. The problem was that when I went back to Maarek’s practice exams as external validation, I only climbed to 73% and then plateaued there.
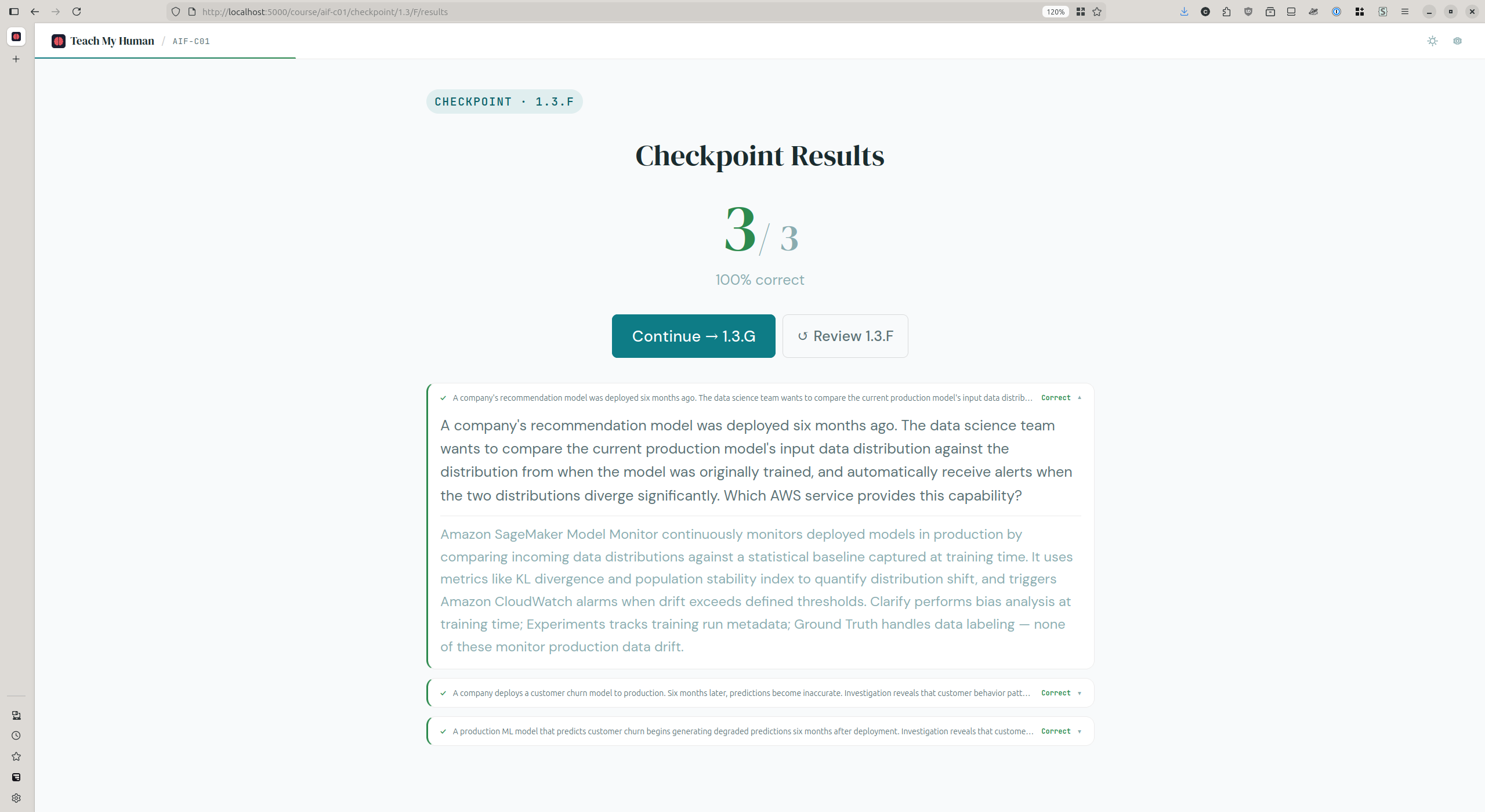
That plateau forced a useful diagnostic exercise. I went through every question I missed on the Maarek exam and categorized each miss into one of three buckets: was it a topic TMH never covered (a content gap), a topic TMH covers but I couldn’t recall (a retention issue), or something TMH taught incorrectly (a content error or hallucination)? Seven of the misses turned out to be content gaps, topics like AWS Trainium vs. Inferentia, the difference between multi-class and multi-label classification, Amazon Personalize, BERT as an encoder architecture, AWS DeepRacer, and the distinction between SageMaker Model Cards, Clarify, and Model Monitor. TMH simply didn’t cover those topics at all.
Fixing those gaps grew the question bank from 196 to 263 questions and added targeted learning material for each one. After that remediation my scores did start climbing again, into the low-to-mid 80s in the week before the exam, and then on the day before the exam I scored 78%, 82%, 83%, and 89% on four practice tests. But taking four practice tests in one day is cramming, the exact thing TMH was designed to prevent, and the gap between that 89% and my actual exam score of 76% suggests that at least some of the practice test improvement was recency-based rather than durable retention.
The Score#
761 out of 1,000. A pass, but barely comfortable. My CCP score was 776 using a simpler process without a custom application, and while the AIF-C01 is a harder exam with more scenario-based questions, more service disambiguation, and a broader scope (so a direct score comparison isn’t perfectly fair), I also spent significantly more time and effort on AIF-C01 and the result wasn’t proportionally better.
I’m not content with a 76%. It’s not something I’d put on a resume with an exclamation mark. It tells me the study process works well enough to pass but not well enough to feel confident. The 13-point gap between my best practice score of 89% and the actual exam at 76% is the most important number in this whole post, and that gap is what needs to close.
What Actually Worked#
TMH wasn’t a waste, though. The diagnostic framework, categorizing misses into coverage gaps, retention issues, and content errors, is a process I’ll absolutely use again. It turned vague frustration into specific, actionable work items, and the seven content gaps I found and fixed were real blind spots that would have cost me points on exam day.
The interleaving mechanism worked too. TMH deliberately pulls quiz questions from all previously studied sections, not just the one you just read. The first time this happened I actually thought it was a bug. I had just finished reading about generative AI fundamentals and got a question about SageMaker Clarify. Turns out that was working as designed. Interleaved practice feels harder and produces worse scores during practice, but the research says it produces better retention on delayed tests, and after going through this process I believe that now.
The source grounding discipline also paid off. Every question in the TMH question bank traces back to an official AWS document, which meant that when I was debugging content gaps I could verify whether TMH was teaching correct information rather than guessing. No hallucinated facts made it into the final question bank, and that gave me confidence that when I got something wrong on a practice test, the issue was in my head and not in the material.
And as much as the local ML pipeline was a distraction from studying, I’d be lying if I said it didn’t help me understand the exam material. When you’ve spent an evening debugging why your embedding model dimensions don’t match your vector database schema, or figuring out why Docling’s page_range parameter needs a tuple instead of a list, the exam questions about data ingestion pipelines and RAG architectures stop being abstract. I wouldn’t recommend “build the thing instead of studying the thing” as a study strategy, but I can’t pretend it didn’t contribute.
What I’d Do Differently#
I have a list of certifications ahead of me (CKA, CKAD, CAPA, Terraform Associate) and here’s what I’m changing for the next one.
First and most importantly, I’m going to schedule the exam before I start studying. For the CCP I set a date and studied toward it. For the AIF-C01 I told myself I’d schedule when I felt ready, and that open-ended timeline expanded to fill seven weeks with non-study activities. Next time I’m picking a date 3-4 weeks out and committing to it the same day I start studying.
Second, I need to separate study blocks from build blocks. If TMH needs development work for the next certification’s content bundle, I’ll do that before the study block starts or after the exam. During the study block the only permitted activities are reading material, doing retrieval practice, and taking practice exams. No theme systems, no dev container migrations, no homelab clusters. Those go on the backburner until the exam is done.
Third, daily retrieval practice with no exceptions. Even 30 minutes of quizzing per day beats a 4-hour engineering session on application improvements. The spacing effect requires consistent, distributed sessions, and I knew this from the research but still didn’t do it consistently. That has to change.
Fourth, one practice test the day before, not four. Use it as a final confidence check and then rest. Walking into the exam depleted from a full day of cramming is counterproductive, and the 13-point score drop from practice to actual suggests that’s exactly what happened.
Fifth, I need to track my time allocation in real time. I’m going to keep a simple log of how many minutes each day go to studying versus building versus other projects. If the study ratio drops below 70%, that’s a red flag. My chat history with Claude AI from this certification makes the ratio painfully clear in hindsight. I just wasn’t tracking it while it was happening.
On the TMH side, I want to add question variation so that each concept is tested from 3-4 different angles with different scenarios and distractor sets. By the end of my study period I was recognizing questions rather than demonstrating understanding, and that’s a sign the question bank isn’t diverse enough. I also plan to start using TMH from day one of the next cert rather than finishing the course first and then building the tool. The application already exists now. I should be generating content and quizzing myself from the first day of study instead of waiting until I’ve passively consumed the entire course.
What’s Next#
The immediate next step is this blog post, documenting what happened while it’s still fresh.
After that, I have three Raspberry Pi 5 boards sitting on my desk waiting to be assembled into a k3s cluster, and I need to get that done before I start the next study block. The cluster will double as hands-on preparation for the Certified Kubernetes Administrator (CKA) exam and as a platform for the Argo suite (CD, Workflows, Events, Rollouts) that I want to learn next. The homelab and the certification feed each other, which is good, but I need to treat the cluster build as a bounded prerequisite task that gets finished before I schedule the exam, not something I tinker with alongside studying. The sequence needs to be: assemble the cluster, generate the TMH content bundle for CKA, schedule the exam, and then the study block begins with no more cluster work until after I’ve tested.
CKAD and the Terraform Associate are further down the road and I’m intentionally not thinking about those yet. The lesson from this certification is to focus on one thing at a time, and I’ve already proven I’m not great at following that advice.
The real test is whether I can apply the process changes I listed above (schedule the exam early, separate study blocks from build blocks, daily retrieval practice, track my time allocation) or whether I’ll find another interesting engineering project to hide in. I know which outcome is more likely. I’m going to try for the other one.
The Honest Summary#
I passed the AWS AI Practitioner certification. I built a study tool grounded in learning science research, identified a real problem with passive learning, designed a solution, and used it to close specific knowledge gaps. All of that is true. It’s also true that I spent seven weeks on a three-week exam, scored lower than my previous certification despite more effort, and consistently chose comfortable engineering work over uncomfortable retrieval practice. The tool I built to solve a focus problem became the focus problem.
76% is a pass. It’s not the score I wanted. The next one needs to be better, not just the score, but the process.
Well, that’s all. See you in the next one.
P.S. I used Claude AI as a sounding board while writing this post. It also helped me search through my project chat history to reconstruct the timeline and pull out specific data points. The ideas, the self-criticism, and the final edits are mine.s